
GoogleDriveにアップロードしたファイルをダウンロードするのに便利なgdownだけど、大量のファイルをダウンロードしたり、大きなファイルをダウンロードしようとしたりすると、何かエラーを吐く。
Cannot retrieve the public link of the file. You may need to change
the permission to 'Anyone with the link', or have had many accesses.
gdownでのアクセス過多による制限っぽいんだけど、これが結構シビアっぽく、条件もよくわからなかったので、
「じゃあgdownを使わずにやろう」
というのが今回の趣旨。
環境
python -V
Python 3.11.9
gdownを使う場合
gdownを使う場合はめちゃ簡単。
import gdown
import requests
def get_gdrive_filename(url):
# HTMLを取得
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
raise Exception(
f"対象を取得できません. Status code: {response.status_code}")
# PyQueryでHTMLを解析
doc = pq(html_content)
# ファイル名を含む要素を取得
# Google Driveのページ構造により、ファイル名は 'meta' タグや他のタグに含まれる場合がある
file_name = doc('meta[property="og:title"]').attr('content') # ファイル名の候補
# 結果を表示
if file_name:
print(f"ファイル名: {file_name}")
else:
print("ファイル名が見つかりませんでした。")
return file_name
def download_gdrive_content(url, dl_dir):
# ファイルIDの抽出
file_id = url.split('/d/')[1].split('/')[0]
# ダウンロード用の直接リンクを生成
download_url = f"https://drive.google.com/uc?id={file_id}"
# gdriveのDL先ファイル名を取得
filename = get_gdrive_filename(url)
# ダウンロード先のファイルパス
output_filepath = dl_dir + filename
# ファイルをダウンロード
gdown.download(download_url, output_filepath, quiet=False)
gdrive_url = 'https://drive.google.com/file/d/XXXXXXXXXXXXXXXXXXXXXXXX/view?usp=sharing'
download_gdrive_content(gdrive_url,'/tmp/download/')
gdown自体、GoogleDriveからダウンロードするために用意されたOSSなので、かなり簡単にダウンロードできる。
また、ダウンロード中もプログレスバー等で視覚的に表示してくれるので、今回の目的のように、大量にダウンロードしたいみたいな要件がなければgdownを使うのをおすすめする。
が、今回の趣旨とは違うので紹介程度に。
gdownを使わないでダウンロードする
gdownを使わないとなると、いつも通りrequestsを使うことになる
import requests
def download_gdrive_content_no_gdown(url, dl_dir):
# ファイルIDの抽出
file_id = url.split('/d/')[1].split('/')[0]
# ダウンロード用の直接リンクを生成
download_url = f"https://drive.google.com/uc?id={file_id}"
# gdriveのDL先ファイル名を取得
filename = get_gdrive_filename(url)
print('DL_LINK: ' + download_url)
# 保存先のパスを作成
save_path = dl_dir + filename
# リクエストを送信してファイルをダウンロード
response = requests.get(download_url, stream=True)
if response.status_code == 200:
output_filepath = dl_dir + filename
# ファイルを保存
with open(output_filepath, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"ファイルが正常にダウンロードされました: {save_path}")
ダウンロード用の直接リンクを作ってあげれば、それをリクエストするだけでダウンロードできる。
じゃあgdownよりも簡単かというとそう単純なものでもなかった。
直接リンクに移動したときにたまにこんな画面が出ることがある。

これが出ると、直接リンク先のこのHTMLをダウンロードしてしまい、本当にほしいコンテンツを取得できない。
これを防ぐためには、以下のようなリンクに作り変える必要がある。
'https://drive.usercontent.google.com/download?id=[id]&authuser=0&confirm=t&uuid=[uuid]
authuserは0、confirm=tで固定っぽいが、問題はuuid。
レスポンスヘッダにもないし、どこを参照するパラメータなのかあくせく探し回った結果、html内に埋め込まれていることを発見。
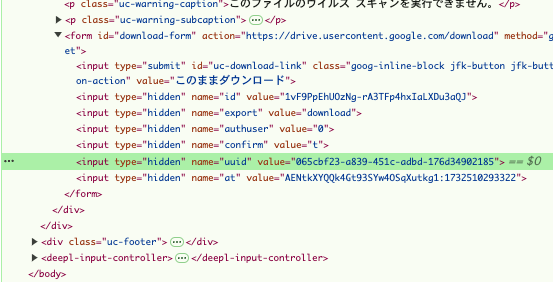
というわけで、webスクレイピングを使ってhtml内のuuidを取得することになる。
from pyquery import PyQuery as pq
# 直接リンクを引数にいれるとUUIDとかつけたウィルスチェックをパスするリンクを生成する
def create_gdrive_pass_viruscheck_link(url):
# ページのHTMLを取得
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
# HTTPで取れなかったら例外を投げる
raise Exception(
f"Failed to fetch the page. Status code: {response.status_code}")
# PyQueryでHTMLを解析
doc = pq(html_content)
# name="uuid" を持つ input 要素を検索し、value を取得
id = doc('input[name="id"]').attr('value')
authuser = doc('input[name="authuser"]').attr('value')
if authuser == None:
authuser = '0'
confirm = doc('input[name="confirm"]').attr('value')
uuid = doc('input[name="uuid"]').attr('value')
at = doc('input[name="at"]').attr('value')
print(id, authuser, confirm, uuid, at)
# リンクを生成
dl_link = 'https://drive.usercontent.google.com/download?' + 'id=' + id + \
'&authuser=' + authuser + '&confirm=' + \
confirm + '&uuid=' + uuid # + '&at' + at
return dl_link
WEBスクレイピングにはpyqueryを利用。
htmlからidとuuid等を取得して、それを使ってリンクを作成する。
これによって真の直接ダウンロードリンクを生成できる。
というわけで全体。
import requests
from pyquery import PyQuery as pq
def get_gdrive_filename(url):
# HTMLを取得
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
raise Exception(
f"Failed to fetch the page. Status code: {response.status_code}")
# PyQueryでHTMLを解析
doc = pq(html_content)
# ファイル名を含む要素を取得
# Google Driveのページ構造により、ファイル名は 'meta' タグや他のタグに含まれる場合があります
file_name = doc('meta[property="og:title"]').attr('content') # ファイル名の候補
# 上でファイル名が取れなかった場合、以下を試す
if file_name == None:
file_name = doc('span.uc-name-size a').text()
if file_name == None or file_name == '':
file_name = get_content_disposition(url).split('"')[1]
# 結果を表示
if file_name:
print(f"ファイル名: {file_name}")
else:
print("ファイル名が見つかりませんでした。")
return file_name
def create_gdrive_pass_viruscheck_link(url):
# ページのHTMLを取得
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
# HTTPで取れなかったら例外を投げる
raise Exception(
f"Failed to fetch the page. Status code: {response.status_code}")
# PyQueryでHTMLを解析
doc = pq(html_content)
# print(html_content)
# name="uuid" を持つ input 要素を検索し、value を取得
id = doc('input[name="id"]').attr('value')
authuser = doc('input[name="authuser"]').attr('value')
if authuser == None:
authuser = '0'
confirm = doc('input[name="confirm"]').attr('value')
uuid = doc('input[name="uuid"]').attr('value')
at = doc('input[name="at"]').attr('value')
print(id, authuser, confirm, uuid, at)
dl_link = 'https://drive.usercontent.google.com/download?' + 'id=' + id + \
'&authuser=' + authuser + '&confirm=' + \
confirm + '&uuid=' + uuid # + '&at' + at
return dl_link
def get_content_disposition(url):
# HEADリクエストでヘッダーだけを取得
response = requests.head(url, allow_redirects=True)
response.raise_for_status() # エラーがあれば例外をスロー
# ヘッダーからContent-Dispositionを取得
content_disposition = response.headers.get("Content-Disposition")
if content_disposition:
print(f"Content-Disposition: {content_disposition}")
return content_disposition
else:
print("Content-Dispositionヘッダーが見つかりませんでした")
return None
def download_gdrive_content_no_gdown(url, dl_dir):
# ファイルIDの抽出
file_id = url.split('/d/')[1].split('/')[0]
# ダウンロード用の直接リンクを生成
download_url = f"https://drive.google.com/uc?id={file_id}"
# gdriveのDL先ファイル名を取得
filename = get_gdrive_filename(url)
print('DL_LINK: ' + download_url)
# 保存先のパスを作成
save_path = dl_dir + filename
# リクエストを送信してファイルをダウンロード
response = requests.get(download_url, stream=True)
if response.status_code == 200:
# ファイル名を取得(Content-Disposition ヘッダーから)
if 'Virus scan warning' in response.text:
viruscheck_url = create_gdrive_pass_viruscheck_link(download_url)
response = requests.get(viruscheck_url, stream=True)
output_filepath = dl_dir + filename
# ファイルを保存
with open(output_filepath, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"ファイルが正常にダウンロードされました: {save_path}")
gdrive_url = 'https://drive.google.com/file/d/XXXXXXXXXXXXXXXXXXXXXXXX/view?usp=sharing'
download_gdrive_content_no_gdown(gdrive_url,'/tmp/download/')
これでサイズの大きなファイルを取得する際にもちゃんと認証パスしてダウンロードできる。
ここまで書いておいて何だけど、やっぱりgdown使ったほうが楽だわ。

コメント